
Hallo liebe Leser,
Zuletzt haben wir uns auf AI News Daily mit den Grundlagen des Data Mining beschäftigt. Heute tauchen wir weiter in die Materie ein des Data Minings ein und erkunden eines seiner Schlüsselverfahren: das Clustering im Data Mining. Dieses Verfahren ist nicht nur ein grundlegender Bestandteil der Datenanalyse, sondern auch ein Fenster, durch das wir die verborgenen Muster und Strukturen in großen Datenmengen erkennen können.
Hier geht es zum letzten Artikel zu Data Mining.
Contents
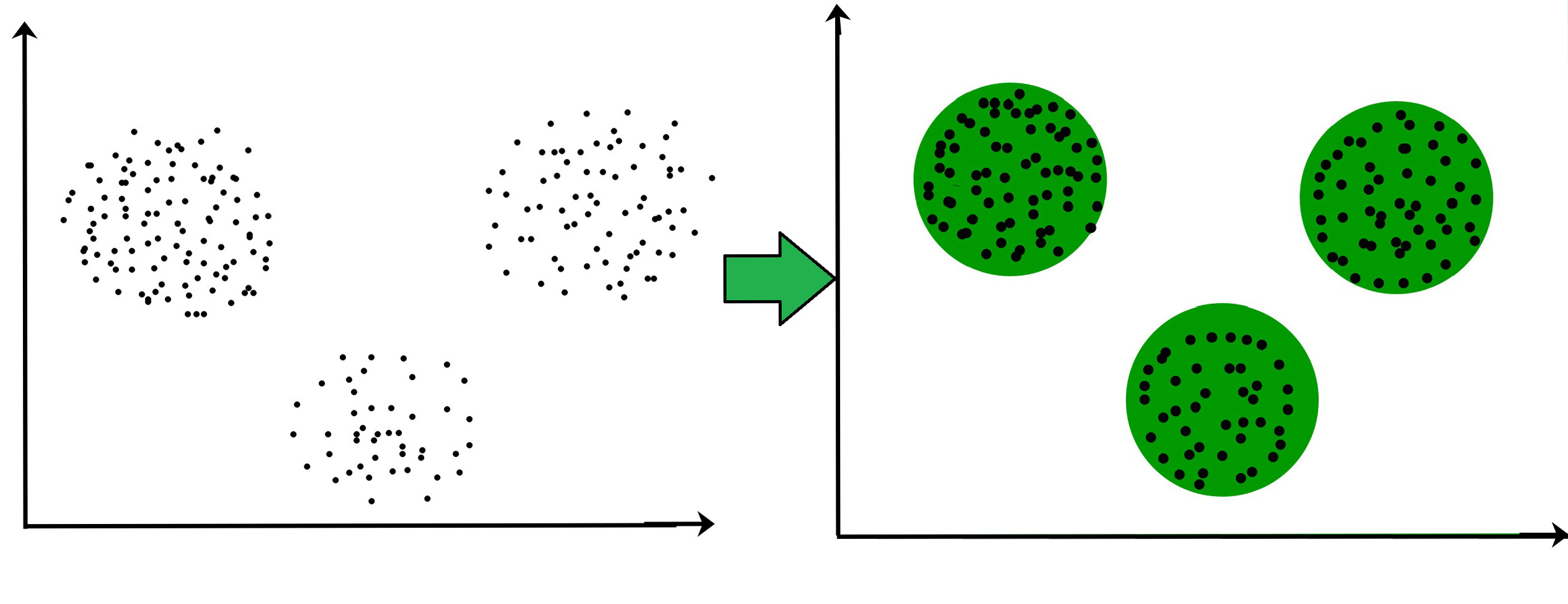
Was ist Clustering im Data Mining?
Clustering im Data Mining ist ein Prozess, bei dem große Datensätze in sinnvolle Untergruppen (Cluster) unterteilt werden. Diese Gruppen werden so gebildet, dass Datenpunkte innerhalb eines Clusters möglichst ähnliche Eigenschaften aufweisen, während sie sich von Datenpunkten in anderen Clustern deutlich unterscheiden. Stellen Sie sich das wie die Organisation einer riesigen Bibliothek vor: Bücher werden nach Genres, Autoren oder Themen gruppiert, um die Suche und das Verständnis zu erleichtern.
Die Bedeutung des Clusterings
In der heutigen datengetriebenen Welt, in der Unternehmen und Organisationen mit riesigen Mengen an Informationen konfrontiert sind, ist Clustering ein unverzichtbares Werkzeug. Es hilft, verborgene Muster und Beziehungen in den Daten zu entdecken, die sonst unerkannt bleiben würden. Von der Marktsegmentierung über die medizinische Forschung bis hin zur Erkennung von Betrugsfällen – Clustering hat vielfältige Anwendungen.
Verschiedene Clustering-Methoden
Es gibt verschiedene Methoden des Clusterings, jede mit ihren eigenen Stärken und Anwendungsbereichen:
- K-Means Clustering: Eine der bekanntesten Methoden, bei der Datenpunkte so in k Gruppen eingeteilt werden, dass die Summe der Quadrate der Abstände der Datenpunkte zu ihrem jeweiligen Gruppenmittelpunkt minimiert wird.
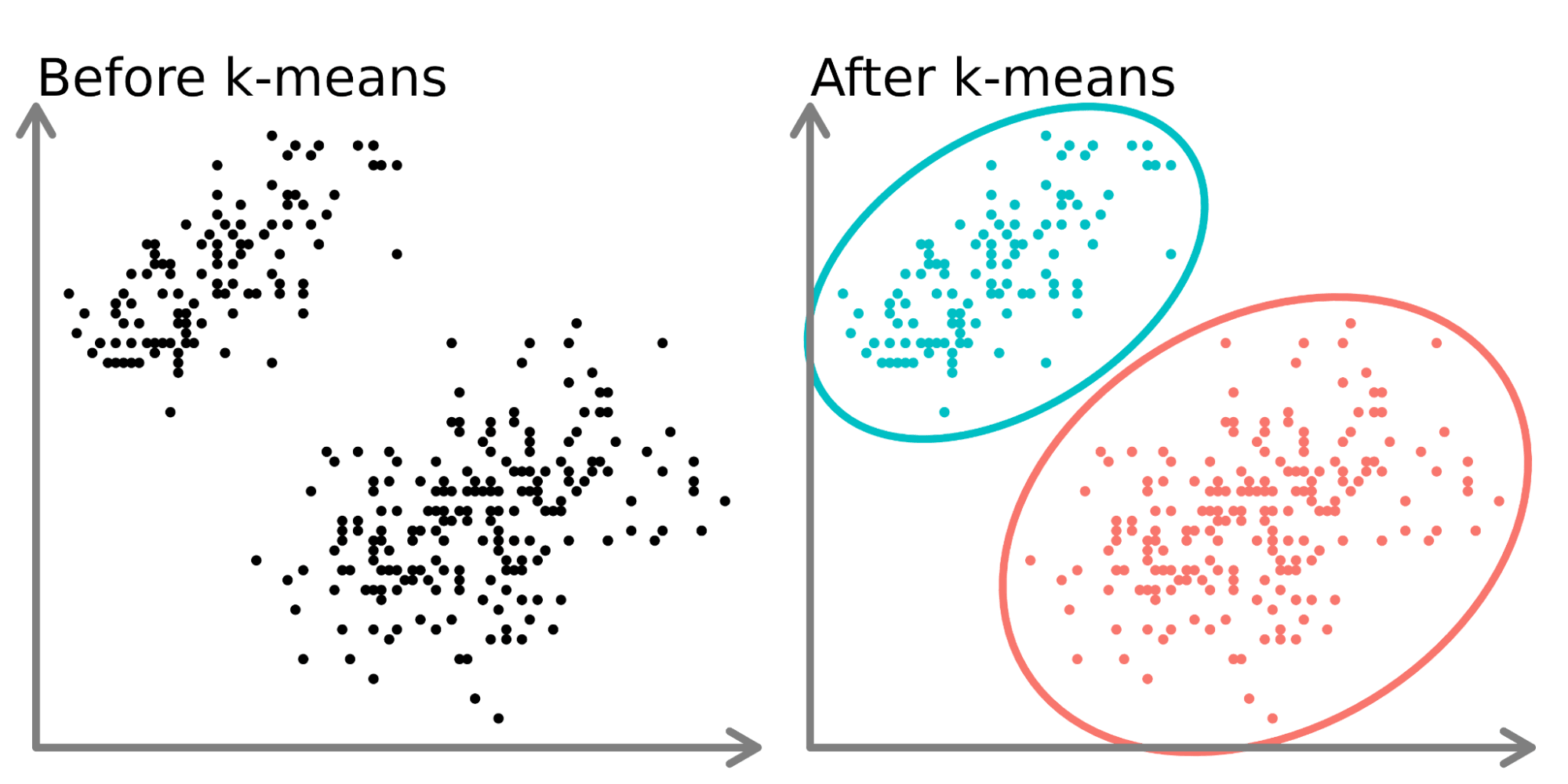
- Hierarchisches Clustering: Diese Methode erstellt eine Baumstruktur von Clustern. Sie ist besonders nützlich, wenn die Beziehung zwischen den Clustern verstanden werden soll.
- Dichtebasiertes Clustering: Zum Beispiel DBSCAN (Density-Based Spatial Clustering of Applications with Noise), das Cluster auf der Grundlage der Dichte der Datenpunkte bildet. Diese Methode ist gut geeignet, um Cluster unterschiedlicher Formen zu finden und Ausreißer zu identifizieren.
Anwendungsbeispiele des Clusterings
- Kunden-Segmentierung: Unternehmen nutzen Clustering, um Kunden in verschiedene Gruppen zu unterteilen und so maßgeschneiderte Marketingstrategien zu entwickeln.
- Genomforschung: In der Biologie hilft Clustering dabei, genetische Muster zu identifizieren, die für bestimmte Krankheiten oder Merkmale relevant sind.
- Bilderkennung: In der Bildverarbeitung wird Clustering verwendet, um Objekte in Bildern zu identifizieren und zu klassifizieren.
Herausforderungen beim Clustering im Data Mining
Trotz seiner Nützlichkeit ist Clustering kein einfacher Prozess. Herausforderungen umfassen die Wahl der richtigen Clustering-Methode, die Bestimmung der Anzahl der Cluster und den Umgang mit hochdimensionalen Daten. Darüber hinaus kann die Interpretation der Clusterergebnisse subjektiv sein und erfordert oft Expertenwissen.
Die Zukunft des Clusterings
Mit dem Fortschritt in der KI und maschinellem Lernen wird Clustering im Data Mining immer ausgefeilter. Technologien wie Deep Learning eröffnen neue Möglichkeiten, noch komplexere Muster in Daten zu erkennen und zu interpretieren. Die Integration von Clustering-Verfahren in Echtzeitanwendungen und die Verarbeitung von Streaming-Daten sind weitere spannende Entwicklungen.
Fazit
Clustering im Data Mining ist eine mächtige Technik, die uns hilft, die Geheimnisse in unseren Daten zu entschlüsseln. Es ist ein Schlüsselwerkzeug für Datenwissenschaftler und Analysten, um aus großen Datenmengen wertvolle Einsichten zu gewinnen. In einer Welt, die zunehmend von Daten angetrieben wird, wird die Bedeutung des Clusterings nur noch weiter zunehmen.
Alle weiteren Beiträge rund um das Thema Data Mining findest du hier.
Bildquellen:
https://www.geeksforgeeks.org/clustering-high-dimensional-data-in-data-mining/
https://www.datacamp.com/tutorial/k-means-clustering-python
Quelle:
https://link.springer.com/article/10.1007/s11576-008-0108-z
Entdecke mehr von AI News Daily
Subscribe to get the latest posts sent to your email.