
In der rasant fortschreitenden Welt der künstlichen Intelligenz und des maschinellen Lernens stellt das Verständnis natürlicher Sprache eine der größten Herausforderungen und Chancen dar. Massive Multitask Language Understanding (MMLU) steht im Zentrum dieser Entwicklung und bietet einfachen Benchmark, der die Grenzen aktueller Sprachmodelle testet und erweitert.
Contents
Was ist Massive Multitask Language Understanding (MMLU)?
MMLU ist ein Benchmark für NLP-Modelle, der darauf abzielt, das allgemeine Weltwissen und die Problemlösungsfähigkeiten dieser Modelle zu testen und zu beurteilen. Er umfasst eine breite Palette von Wissensgebieten, einschließlich, aber nicht beschränkt auf MINT-Fächer (Mathematik, Informatik, Naturwissenschaften und Technik), Geistes- und Sozialwissenschaften sowie viele weitere Bereiche.
Der MMLU-Benchmark ist von entscheidender Bedeutung, da er die tiefergehenden Fähigkeiten von Sprachmodellen zur Anwendung ihres Weltwissens herausfordert. Während viele existierende Benchmarks sich auf spezifische Aufgabenstellungen oder das Verständnis von „gesundem Menschenverstand“ konzentrieren, geht MMLU darüber hinaus, indem es Modelle mit komplexen Fragestellungen aus einer Vielzahl von Fachgebieten konfrontiert. Dieser Ansatz hilft, die Grenzen der aktuellen Sprachtechnologien zu erweitern und fördert die Entwicklung fortgeschrittener Modelle, die ein breiteres Spektrum menschlicher Wissens- und Verständnisfähigkeiten nachahmen können.

Entwicklung und Inhalt von MMLU
Entwickelt von einem Team führender Forscher, unter anderem von der UC Berkeley und Columbia University, wurde Massive Multitask Language Understanding erstmals in einem Paper auf der ICLR 2021 vorgestellt. Der Benchmark deckt 57 Fachbereiche ab und beinhaltet insgesamt 15.908 Fragen, die von Studenten aus verschiedenen Online-Quellen gesammelt wurden. Diese Fragen reichen von einfachem Grundwissen bis hin zu fortgeschrittenem Expertenwissen und sind in einen Few-Shot-Entwicklungsdatensatz, einen Validierungsdatensatz und einen Prüfungsdatensatz unterteilt.
Bewertung des Massive Multitask Language Understanding Benchmarks
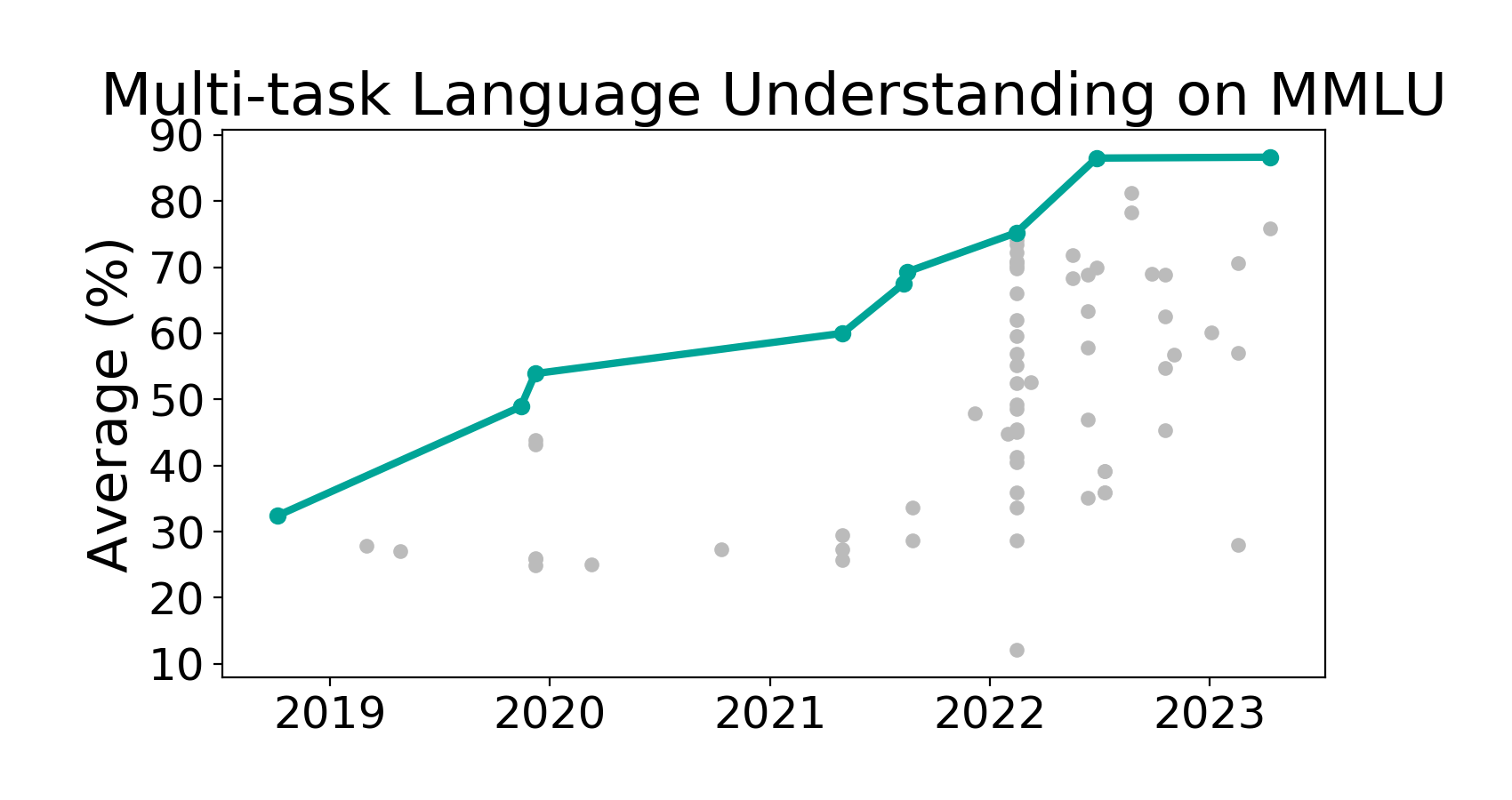
Die Bewertung des MMLU Benchmarks bietet einen tiefgreifenden Einblick in die aktuellen Fähigkeiten und Grenzen von Sprachverarbeitungsmodellen. MMLU, eine umfassende Prüfung für KI-Modelle, deckt eine breite Palette von Fachgebieten ab und fordert die Modelle heraus, ihr Wissen und ihre Problemlösungskompetenz unter Beweis zu stellen. Dieser Benchmark unterscheidet sich von früheren Ansätzen durch seine Vielfalt an Aufgaben und die Tiefe des erforderlichen Wissens, was ihn zu einem wesentlichen Werkzeug für die Bewertung der Generalisierungsfähigkeit von KI-Systemen macht.
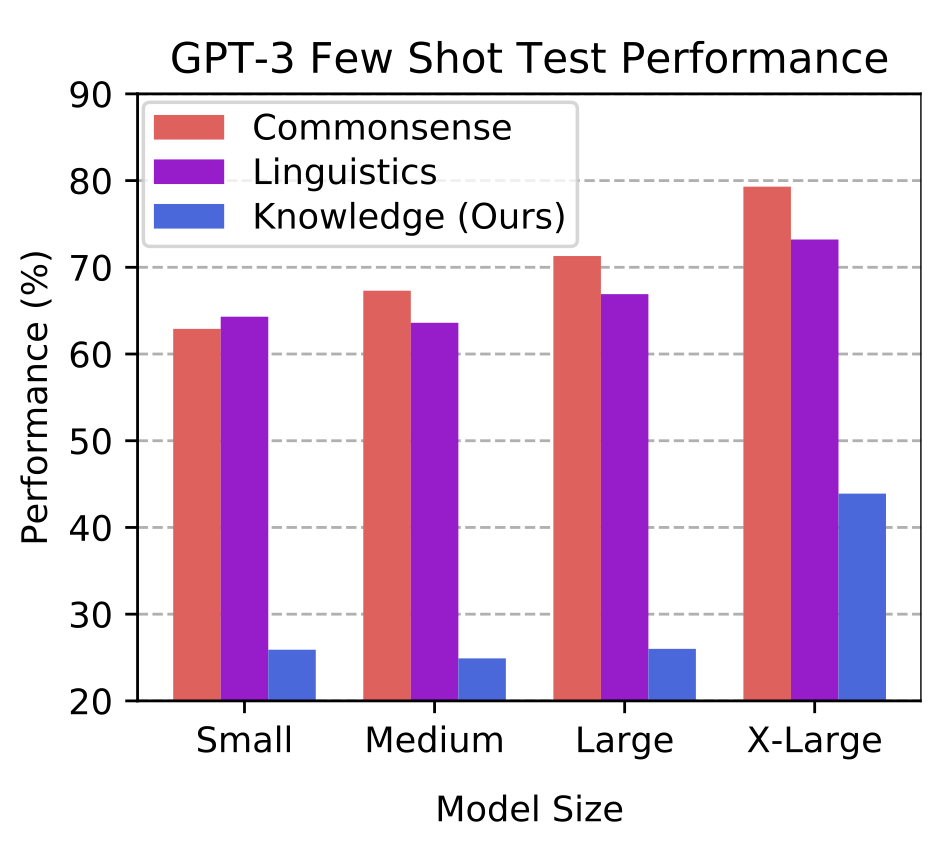
Die Ergebnisse von Massive Multitask Language Understanding zeigen signifikante Unterschiede in der Leistungsfähigkeit moderner Sprachmodelle, insbesondere wenn es um komplexe Aufgabenstellungen geht. Während Modelle wie GPT-3 in einigen Bereichen beeindruckende Leistungen erbringen, offenbaren sie in anderen, vor allem in solchen, die tiefgreifendes Fachwissen oder nuanciertes Verständnis erfordern, deutliche Schwächen. Diese Ergebnisse betonen die Notwendigkeit weiterer Forschung und Entwicklung, um Modelle zu schaffen, die nicht nur ein breites Spektrum von Wissen abdecken, sondern dieses Wissen auch effektiv in vielfältigen und anspruchsvollen Kontexten anwenden können.
Die Bewertung legt nahe, dass trotz beeindruckender Fortschritte in der KI und maschinellem Lernen, insbesondere im Bereich des Natural Language Processing (NLP), noch erhebliche Herausforderungen bestehen. Die Fähigkeit, komplexe Probleme über ein weites Feld von Disziplinen hinweg zu lösen, bleibt ein Schlüsselindikator für das Verständnis und die Intelligenz von Sprachmodellen. MMLU dient somit nicht nur als Benchmark für die aktuelle Leistung, sondern auch als Richtschnur für zukünftige Verbesserungen und Innovationen im Bereich der künstlichen Intelligenz.
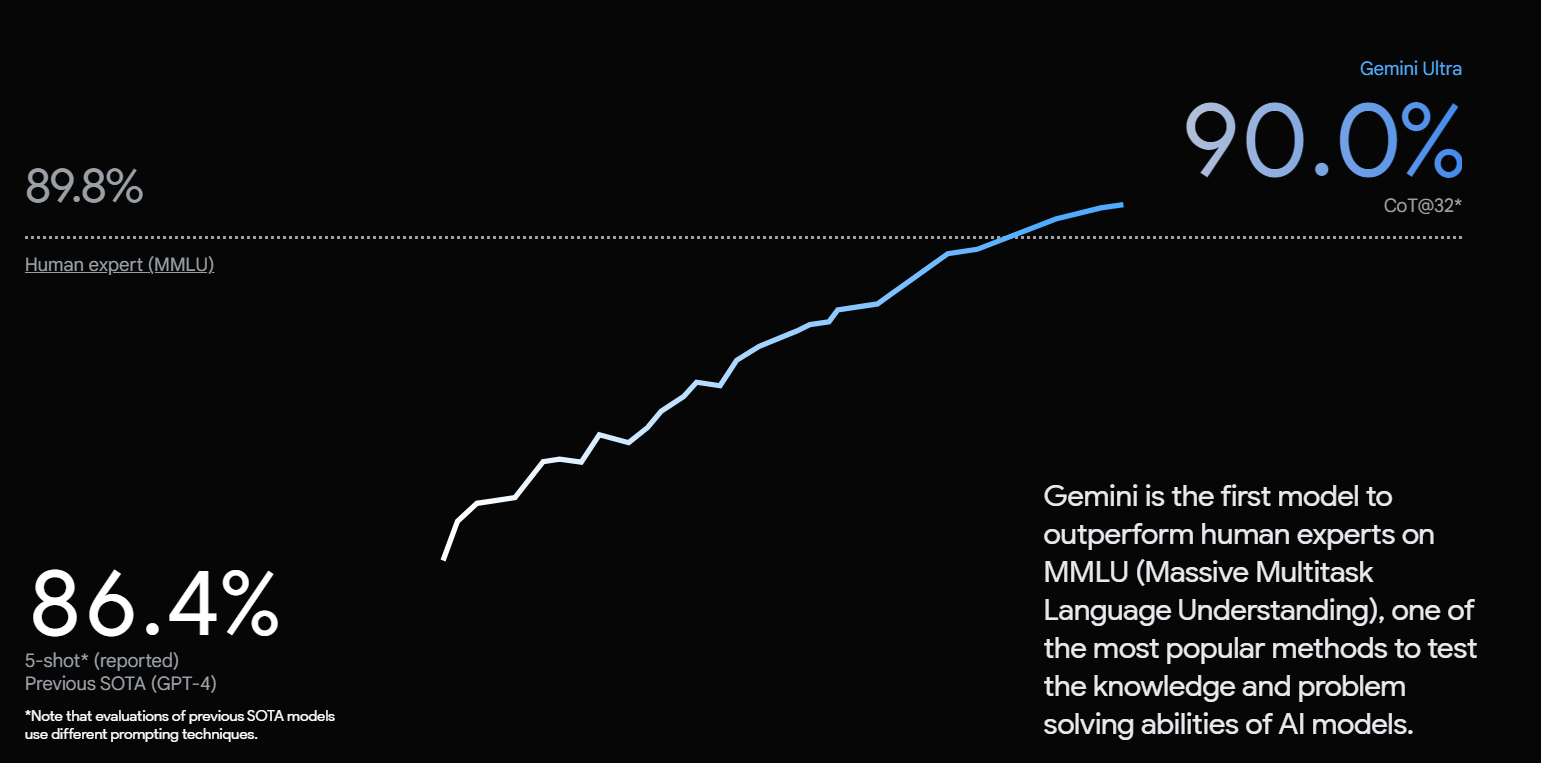
Übrigens: Googles Gemini schneidet in der Benchmark nach eigenen Aussagen bisher am besten ab.
Die Zukunft von Massive Multitask Language Understanding
Massive Multitask Language Understanding markiert einen wichtigen Schritt in der Evolution der KI, indem es ein breites Spektrum von Fähigkeiten testet, die für ein tiefgreifendes Verständnis natürlicher Sprache erforderlich sind. Die Herausforderungen, die es darstellt, und die Ergebnisse, die es hervorbringt, bieten wertvolle Einblicke in die aktuellen Grenzen und Potenziale von Sprachmodellen. Es ist ein Aufruf an die KI-Gemeinschaft, über traditionelle Benchmarks hinauszugehen und Modelle zu entwickeln, die ein umfassenderes und nuancierteres Verständnis der Welt zeigen.
Für Entwickler, Forscher und KI-Enthusiasten bietet MMLU eine einzigartige Gelegenheit, die Fähigkeiten moderner Sprachmodelle zu testen, zu vergleichen und zu verbessern. Es ist ein Schritt in Richtung der Entwicklung von KI-Systemen, die nicht nur Sprache verstehen, sondern auch die komplexe und vielfältige Natur menschlichen Wissens und Denkens.
Weitere Begriffe aus der Welt der künstlichen Intelligenz werden in unserer Rubrik Einfach erklärt behandelt.
FAQs
Was ist MMLU?
MMLU steht für Massive Multitask Language Understanding und ist ein Benchmark, der die Fähigkeit von KI-Sprachmodellen testet, allgemeines Weltwissen über verschiedene Fachgebiete hinweg anzuwenden.
2. Warum ist MMLU wichtig?
MMLU ist wichtig, weil es nicht nur die Breite des Wissens von Sprachmodellen misst, sondern auch ihre Fähigkeit, komplexe Probleme zu lösen, was für die Entwicklung fortschrittlicher KI-Systeme essentiell ist.
3. Wer hat MMLU entwickelt?
Massive Multitask Language Understanding wurde von einem Forscherteam aus renommierten Universitäten wie UC Berkeley und Columbia University entwickelt und erstmals in einem Paper auf der ICLR 2021 vorgestellt.
4. Welche Bereiche deckt MMLU ab?
Der Benchmark umfasst 57 Fachgebiete, darunter MINT-Fächer, Geistes- und Sozialwissenschaften, Geschichte und viele mehr, mit Fragen von einfachem bis zu fortgeschrittenem Niveau.
5. Wie werden die Modelle in MMLU bewertet?
Modelle werden in Zero-Shot- und Few-Shot-Einstellungen getestet, basierend auf ihrer Fähigkeit, Multiple-Choice-Fragen über eine breite Palette von Fachgebieten hinweg zu beantworten.
Zum Paper:
https://arxiv.org/pdf/2009.03300.pdf
https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
Entdecke mehr von AI News Daily
Subscribe to get the latest posts sent to your email.